library(tidyverse)
library(brms)
library(posterior)
dir.create("outputs", showWarnings = FALSE)
dir.create("outputs/models", recursive = TRUE, showWarnings = FALSE)
dir.create("outputs/tables", recursive = TRUE, showWarnings = FALSE)
dir.create("outputs/summaries", recursive = TRUE, showWarnings = FALSE)A Detection-Aware Hierarchical Approach to Imperfect Environmental Sensing
Methane Leak Monitoring Across Repeated Surveys
Supplementary Note: Without a thesis for this paper to contribute to, my goal was to demonstrate a working knowledge of statistical knowledge gained from the EcoStats course, while also improving my ability to present data and build a quarto/github workflow, presenting data is my core interest. As a result, there is no complete existing datset to analyze and the monitoring dataset used here was constructed using open data and the assistance of AI. Additionally, copilot was used to edit Quarto formatting to ensure formatting and functionality when publishing.
1 Background
I have a repeated-survey methane monitoring dataset. Each site is visited multiple times within one monitoring window. For each survey, I record whether a methane leak was detected, along with survey conditions such as cloud cover and sensor type. At the site level, I also have infrastructure age and region.
The key problem is that a nondetection is ambiguous. A zero in the observed data can mean that no leak was present, but it can also mean that a leak was present and the monitoring system missed it.
That is the whole statistical tension in this project.
So our data story is not just “did we detect a leak?” It is:
site status process: Is there actually a leak at this site?
observation process: If there is a leak, do survey conditions allow us to detect it?
1.1 Monitoring design and data structure
This analysis uses a repeated-survey methane monitoring dataset with 24 sites distributed across 4 regions and 4 surveys per site, for a total of 96 survey observations. The four surveys occur within a single monitoring window, so site status is treated as fixed across visits. Site age is used as a predictor of occurrence, while cloud cover and sensor type are used as predictors of detection. A benchmark-confirmed site-status variable also allows the site-level occurrence model to be evaluated against known status rather than relying only on observed detection.
1.2 How does this inform our model?
The outcomes of interest!
Whether a site was ever detected, whether a leak was present, and whether a leak was detected during a given survey are all binary, so a Bernoulli model with a logit link is the natural framework, so our response is probability rather than a continuous value. The detection model also functions as a multiple regression because it estimates the effects of cloud cover and sensor type at the same time. The occurrence model adds a region random intercept, allowing baseline leak probability to vary across regions rather than assuming all sites share the same starting point.
Parameters are represented as distributions of plausible values rather than as single fixed estimates, and uncertainty is summarized with posterior means and credible intervals. More broadly, I aim to demonstrate Bayesian regression, moving beyond a single simple regression and show how generalized linear models, partial pooling, and basic overfitting control can be used together in an environmental monitoring problem.
2 Overview
First, we analyze a repeated-survey methane monitoring dataset with imperfect detection. The benchmark data files are included with the project, so the analysis begins by reading in the static site-level and survey-level data rather than generating them inside the report.
The three fitted models are:
- naive model:
ever_detected ~ site_age_z - occurrence model:
true_event ~ site_age_z + (1 | region) - conditional detection model:
detected ~ cloud_cover_z + sensor_advanced
2.1 DAG
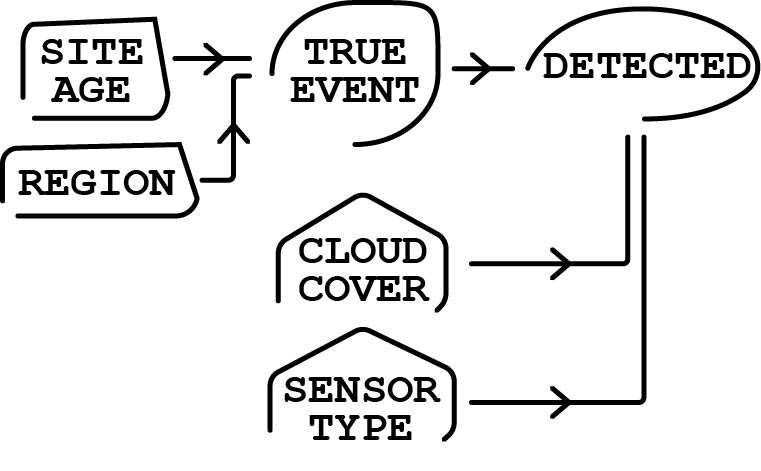
Site age and region affect the probability that a site truly has a leak. True site status then determines whether a detection is even possible. Conditional on a leak being present, cloud cover and sensor type affect the probability that the leak is observed during a survey. My goals was to separate the occurrence process from the observation process without overstating the analysis as a full latent-state model.
3 Read Data
site_df <- readr::read_csv("data/site_df.csv", show_col_types = FALSE) |>
mutate(
site_id = factor(site_id),
region = factor(region, levels = c("North", "South", "Central", "West"))
)
survey_df <- readr::read_csv("data/survey_df.csv", show_col_types = FALSE) |>
mutate(
site_id = factor(site_id),
survey_id = factor(survey_id),
region = factor(region, levels = c("North", "South", "Central", "West")),
sensor_type = factor(sensor_type, levels = c("basic", "advanced"))
)
site_naive_df <- readr::read_csv("data/site_naive_df.csv", show_col_types = FALSE) |>
mutate(
site_id = factor(site_id),
region = factor(region, levels = c("North", "South", "Central", "West"))
)4 Data Summary
tibble(
n_sites = nrow(site_df),
n_survey_rows = nrow(survey_df),
n_regions = dplyr::n_distinct(site_df$region),
surveys_per_site = dplyr::n_distinct(survey_df$survey_id),
true_occurrence_prevalence = mean(site_df$true_event),
observed_survey_detection_prevalence = mean(survey_df$detected),
site_ever_detected_prevalence = mean(site_naive_df$ever_detected)
)# A tibble: 1 × 7
n_sites n_survey_rows n_regions surveys_per_site true_occurrence_prevalence
<int> <int> <int> <int> <dbl>
1 24 96 4 4 0.542
# ℹ 2 more variables: observed_survey_detection_prevalence <dbl>,
# site_ever_detected_prevalence <dbl>5 Statistical Models
Because the continuous predictors are standardized, normal(0, 1) is a sensible weak prior for slopes on the logit scale, while normal(0, 1.5) is a weak prior for intercepts. The random-intercept standard deviation gets an exponential(1) prior.
naive_priors <- c(
prior(normal(0, 1.5), class = "Intercept"),
prior(normal(0, 1), class = "b")
)
occurrence_priors <- c(
prior(normal(0, 1.5), class = "Intercept"),
prior(normal(0, 1), class = "b"),
prior(exponential(1), class = "sd")
)
detection_priors <- c(
prior(normal(0, 1.5), class = "Intercept"),
prior(normal(0, 1), class = "b")
)naive_fit <- readRDS("outputs/models/naive_fit.rds")
occurrence_fit <- readRDS("outputs/models/occurrence_fit.rds")
detection_fit <- readRDS("outputs/models/detection_fit.rds")6 Model summaries
6.1 Choosing Our Analysis
6.1.1 1. Naive model
ever_detected ~ site_age_z
This model treats “detected at least once” as if it were the same as “site truly has a leak.” It is intentionally naive. I use it as a comparison model because it shows what happens when imperfect detection is ignored.
6.1.2 2. Occurrence model
true_event ~ site_age_z + (1 | region)
This is the site-level model. It asks: how does the probability of a leak change with infrastructure age, while allowing regions to have different baselines? I include a region random intercept because sites in the same region are not fully independent, and random intercepts are the standard way to represent group-specific baseline differences.
6.1.3 3. Detection model
detected ~ cloud_cover_z + sensor_advanced, fit only where true_event == 1
This is the survey-level model. It asks how cloud cover and sensor type affect the chance of detecting a leak when a leak is actually present.
So the analysis is split into:
a benchmark occurrence model
a conditional detection model
plus a naive model for contrast
While I could build a more elaborate hierarchical occupancy model that can estimate occupancy and detection jointly, that demands more data and complexity than the scope of what I sat out for the project.
6.2 summary() output
summary(naive_fit) Family: bernoulli
Links: mu = logit
Formula: ever_detected ~ site_age_z
Data: site_naive_df (Number of observations: 24)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.14 0.43 -1.00 0.70 1.00 3189 2728
site_age_z 0.94 0.46 0.12 1.87 1.00 3540 2701
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).summary(occurrence_fit) Family: bernoulli
Links: mu = logit
Formula: true_event ~ site_age_z + (1 | region)
Data: site_df (Number of observations: 24)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Multilevel Hyperparameters:
~region (Number of levels: 4)
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sd(Intercept) 0.58 0.56 0.02 2.01 1.00 1741 1634
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 0.32 0.57 -0.84 1.47 1.00 2117 1497
site_age_z 1.46 0.59 0.40 2.69 1.00 3013 2495
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).summary(detection_fit) Family: bernoulli
Links: mu = logit
Formula: detected ~ cloud_cover_z + sensor_advanced
Data: filter(survey_df, true_event == 1) (Number of observations: 52)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept -0.79 0.39 -1.58 -0.05 1.00 3106 3116
cloud_cover_z -1.03 0.36 -1.77 -0.38 1.00 3033 2833
sensor_advanced 1.33 0.58 0.22 2.49 1.00 3215 2853
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).6.3 Compact posterior summary table
posterior_summary_table <- bind_rows(
posterior_summary(naive_fit) |>
as.data.frame() |>
rownames_to_column("parameter") |>
as_tibble() |>
filter(parameter %in% c("b_Intercept", "b_site_age_z")) |>
mutate(model = "Naive"),
posterior_summary(occurrence_fit) |>
as.data.frame() |>
rownames_to_column("parameter") |>
as_tibble() |>
filter(parameter %in% c("b_Intercept", "b_site_age_z", "sd_region__Intercept")) |>
mutate(model = "Occurrence"),
posterior_summary(detection_fit) |>
as.data.frame() |>
rownames_to_column("parameter") |>
as_tibble() |>
filter(parameter %in% c("b_Intercept", "b_cloud_cover_z", "b_sensor_advanced")) |>
mutate(model = "Detection")
) |>
select(model, parameter, Estimate, Est.Error, Q2.5, Q97.5)
posterior_summary_table# A tibble: 8 × 6
model parameter Estimate Est.Error Q2.5 Q97.5
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Naive b_Intercept -0.141 0.433 -1.00 0.696
2 Naive b_site_age_z 0.943 0.457 0.120 1.87
3 Occurrence b_Intercept 0.320 0.572 -0.842 1.47
4 Occurrence b_site_age_z 1.46 0.590 0.404 2.69
5 Occurrence sd_region__Intercept 0.578 0.561 0.0172 2.01
6 Detection b_Intercept -0.788 0.389 -1.58 -0.0478
7 Detection b_cloud_cover_z -1.03 0.357 -1.77 -0.378
8 Detection b_sensor_advanced 1.33 0.577 0.215 2.49 write_csv(posterior_summary_table, "outputs/summaries/posterior_summary_table.csv")The posterior summary table provides the main coefficient estimates on the logit scale. The most stable patterns in this analysis are the positive association between site age and occurrence and the negative association between cloud cover and detection. The advanced sensor coefficient is positive in direction, which is consistent with better performance, but its interpretation should follow the uncertainty shown in the interval estimate.
6.4 R-hat and ESS Table
diagnostics_table <- bind_rows(
naive_fit |>
as_draws_df() |>
summarise_draws(default_convergence_measures()) |>
as_tibble() |>
filter(variable %in% c("b_Intercept", "b_site_age_z")) |>
mutate(model = "Naive"),
occurrence_fit |>
as_draws_df() |>
summarise_draws(default_convergence_measures()) |>
as_tibble() |>
filter(variable %in% c("b_Intercept", "b_site_age_z", "sd_region__Intercept")) |>
mutate(model = "Occurrence"),
detection_fit |>
as_draws_df() |>
summarise_draws(default_convergence_measures()) |>
as_tibble() |>
filter(variable %in% c("b_Intercept", "b_cloud_cover_z", "b_sensor_advanced")) |>
mutate(model = "Detection")
) |>
select(model, variable, rhat, ess_bulk, ess_tail)
diagnostics_table# A tibble: 8 × 5
model variable rhat ess_bulk ess_tail
<chr> <chr> <dbl> <dbl> <dbl>
1 Naive b_Intercept 1.00 3189. 2728.
2 Naive b_site_age_z 1.00 3540. 2701.
3 Occurrence b_Intercept 1.00 2117. 1497.
4 Occurrence b_site_age_z 1.00 3013. 2495.
5 Occurrence sd_region__Intercept 1.00 1741. 1634.
6 Detection b_Intercept 1.00 3106. 3116.
7 Detection b_cloud_cover_z 1.00 3033. 2833.
8 Detection b_sensor_advanced 1.00 3215. 2853.write_csv(diagnostics_table, "outputs/summaries/diagnostics_table.csv")The convergence diagnostics do not suggest major sampling problems. Values of Rhat near 1 and adequate effective sample sizes indicate that the posterior chains mixed well enough for the current analysis. This does not guarantee a perfect model, but it does support the basic reliability of the posterior summaries.
7 Posterior predictive checks
pp_check(naive_fit, type = "bars", ndraws = 100)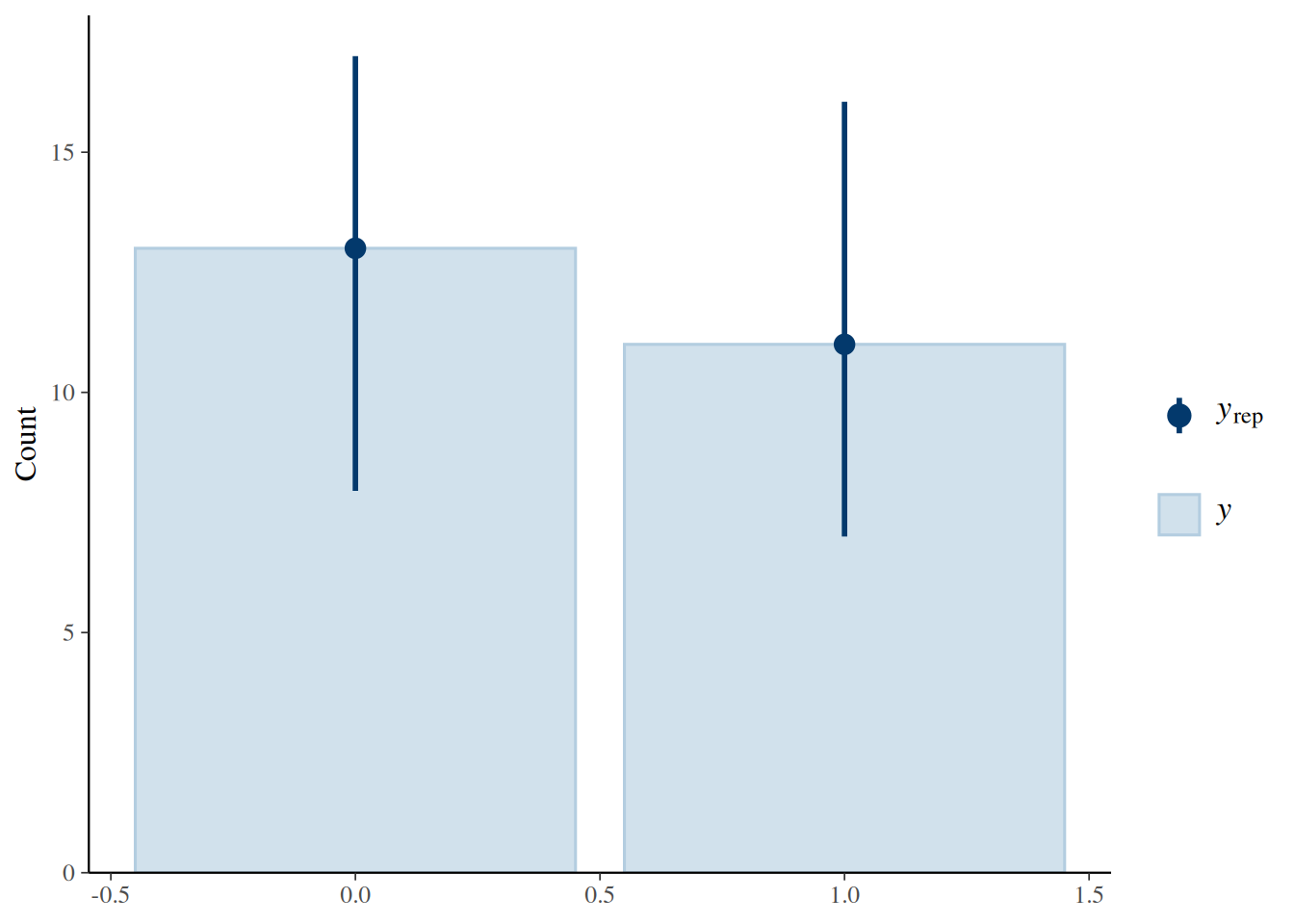
Figure 1. Posterior predictive check for the naive model.
pp_check(occurrence_fit, type = "bars", ndraws = 100)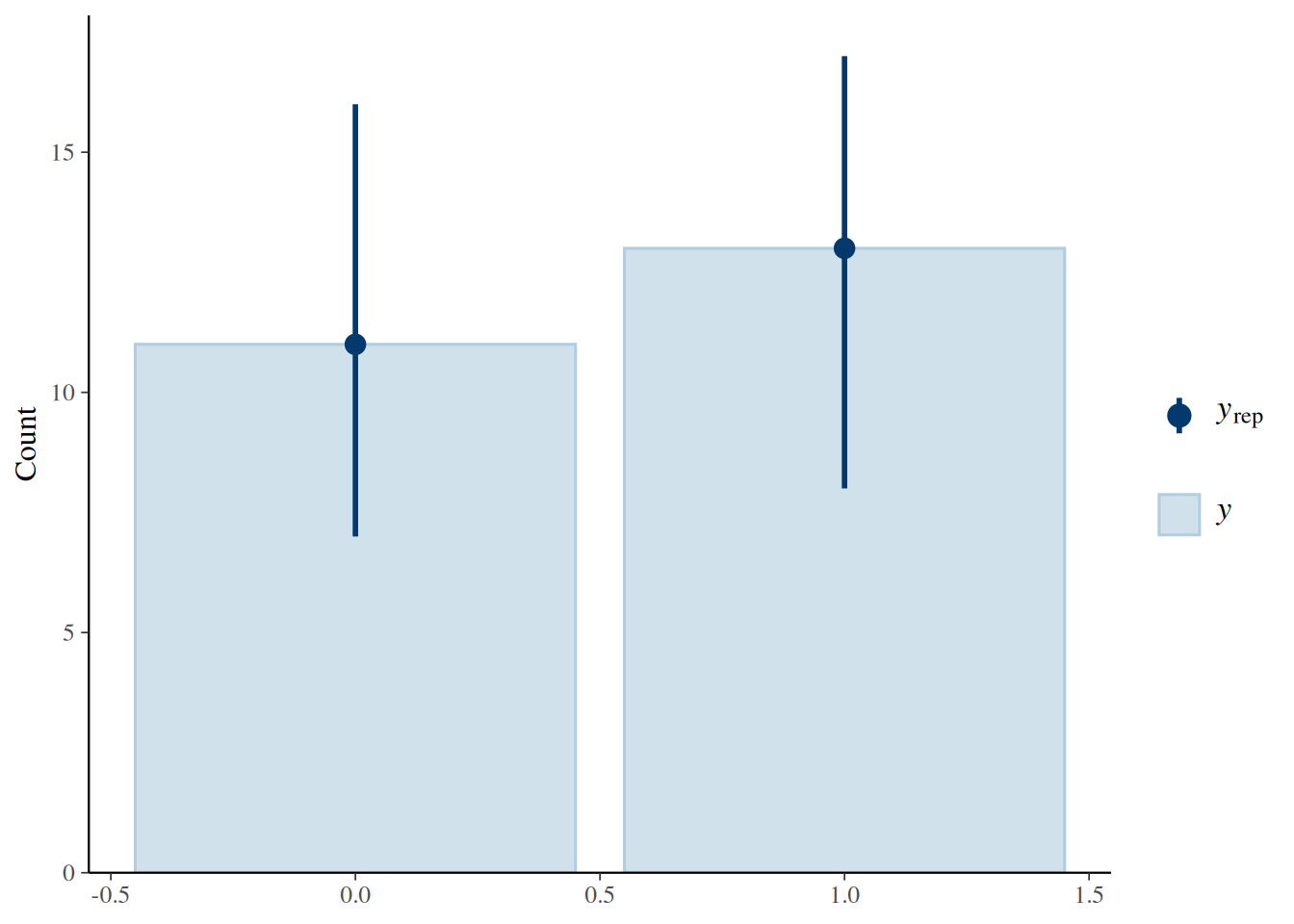
Figure 2. Posterior predictive check for the occurrence model.
pp_check(detection_fit, type = "bars", ndraws = 100)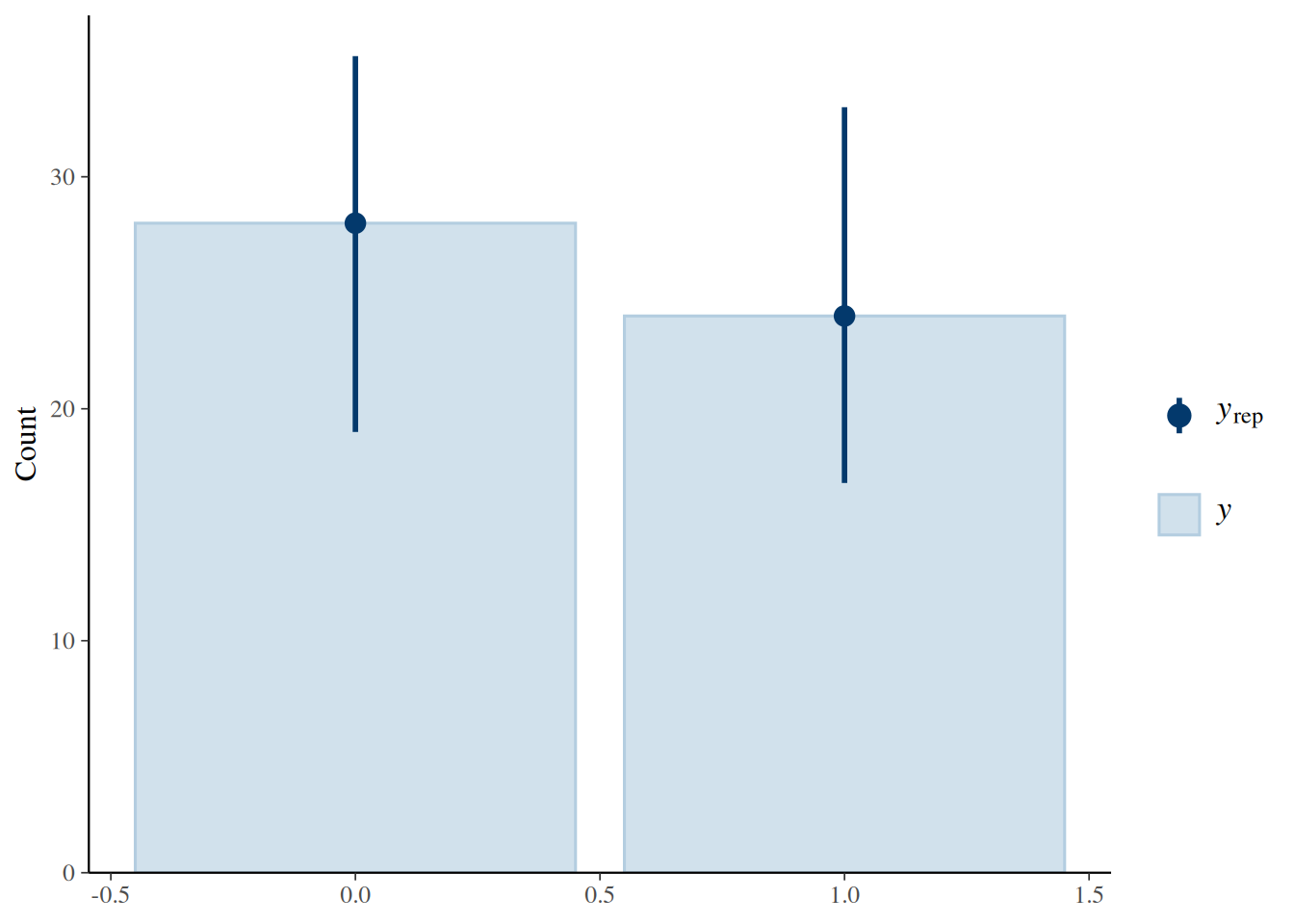
Figure 3. Posterior predictive check for the conditional detection model.
The posterior predictive checks suggest that all three Bernoulli models reproduce the overall proportion of zeros and ones reasonably well. They show that the models are not obviously misfitting the data, but they do not by themselves establish that every predictor relationship has been captured in detail.
8 Repeated surveys and imperfect detection
figure1_sites <- survey_df |>
group_by(region, site_id) |>
summarise(
true_event = first(true_event),
n_detected = sum(detected),
n_surveys = n(),
.groups = "drop"
) |>
mutate(
priority = case_when(
true_event == 1 & n_detected > 0 & n_detected < n_surveys ~ 1L,
true_event == 1 & n_detected > 0 ~ 2L,
true_event == 0 ~ 3L,
TRUE ~ 4L
)
) |>
arrange(region, priority, desc(n_detected), site_id) |>
group_by(region) |>
slice_head(n = 1) |>
ungroup() |>
pull(site_id)
history_df <- survey_df |>
filter(site_id %in% figure1_sites) |>
mutate(
outcome_type = case_when(
true_event == 0 ~ "True absence",
true_event == 1 & detected == 0 ~ "Missed detection",
true_event == 1 & detected == 1 ~ "Detected"
),
outcome_type = factor(
outcome_type,
levels = c("True absence", "Missed detection", "Detected")
)
)
ggplot(history_df, aes(x = survey_id, y = fct_rev(site_id), fill = outcome_type)) +
geom_tile(color = "white", linewidth = 0.5) +
facet_wrap(~ region, scales = "free_y") +
scale_fill_manual(
values = c(
"True absence" = "grey85",
"Missed detection" = "goldenrod2",
"Detected" = "seagreen3"
)
) +
labs(x = "Survey occasion", y = "Site", fill = NULL) +
theme_minimal(base_size = 12) +
theme(
legend.position = "bottom",
panel.grid = element_blank()
)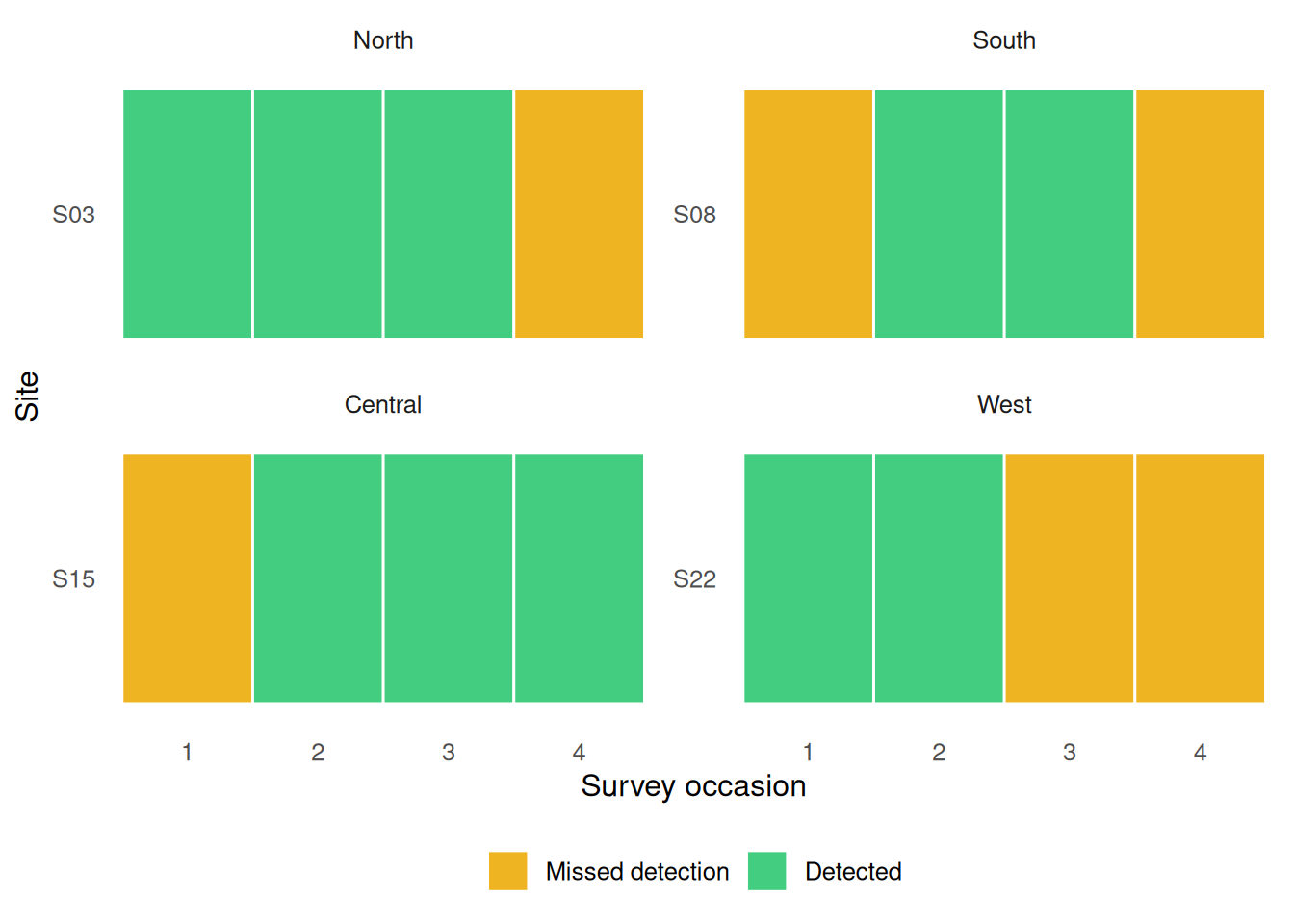
Figure 4. Repeated surveys within one monitoring window. Gray tiles indicate benchmark-confirmed absence, gold tiles indicate missed detection, and green tiles indicate successful detection. The figure shows that even when a leak is present, it is not detected on every survey.
Some sites with benchmark-confirmed leaks were detected on some visits but missed on others, which means a zero in the observed data does not always imply absence. This is the reason a naive model can underestimate occurrence: it treats nondetection and true absence as if they were the same outcome.
9 Predicted detection probability across cloud cover
cloud_seq <- seq(min(survey_df$cloud_cover), max(survey_df$cloud_cover), length.out = 100)
detection_newdata <- expand_grid(
cloud_cover = cloud_seq,
sensor_advanced = c(0, 1)
) |>
mutate(
cloud_cover_z = (cloud_cover - mean(survey_df$cloud_cover)) / sd(survey_df$cloud_cover),
sensor_type = factor(
if_else(sensor_advanced == 1, "advanced", "basic"),
levels = c("basic", "advanced")
)
)
epred_detection <- posterior_epred(
detection_fit,
newdata = detection_newdata,
re_formula = NA
)
detection_plot_df <- as_tibble(t(epred_detection)) |>
mutate(row_id = row_number()) |>
pivot_longer(cols = -row_id, names_to = "draw", values_to = "epred") |>
group_by(row_id) |>
summarise(
mean = mean(epred),
lower = quantile(epred, 0.025),
upper = quantile(epred, 0.975),
.groups = "drop"
) |>
bind_cols(detection_newdata)
ggplot(detection_plot_df, aes(x = cloud_cover, y = mean, color = sensor_type, fill = sensor_type)) +
geom_ribbon(aes(ymin = lower, ymax = upper), alpha = 0.20, linewidth = 0, color = NA) +
geom_line(linewidth = 1.1) +
coord_cartesian(ylim = c(0, 1)) +
labs(
x = "Cloud cover (%)",
y = "Detection probability",
color = "Sensor type",
fill = "Sensor type"
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")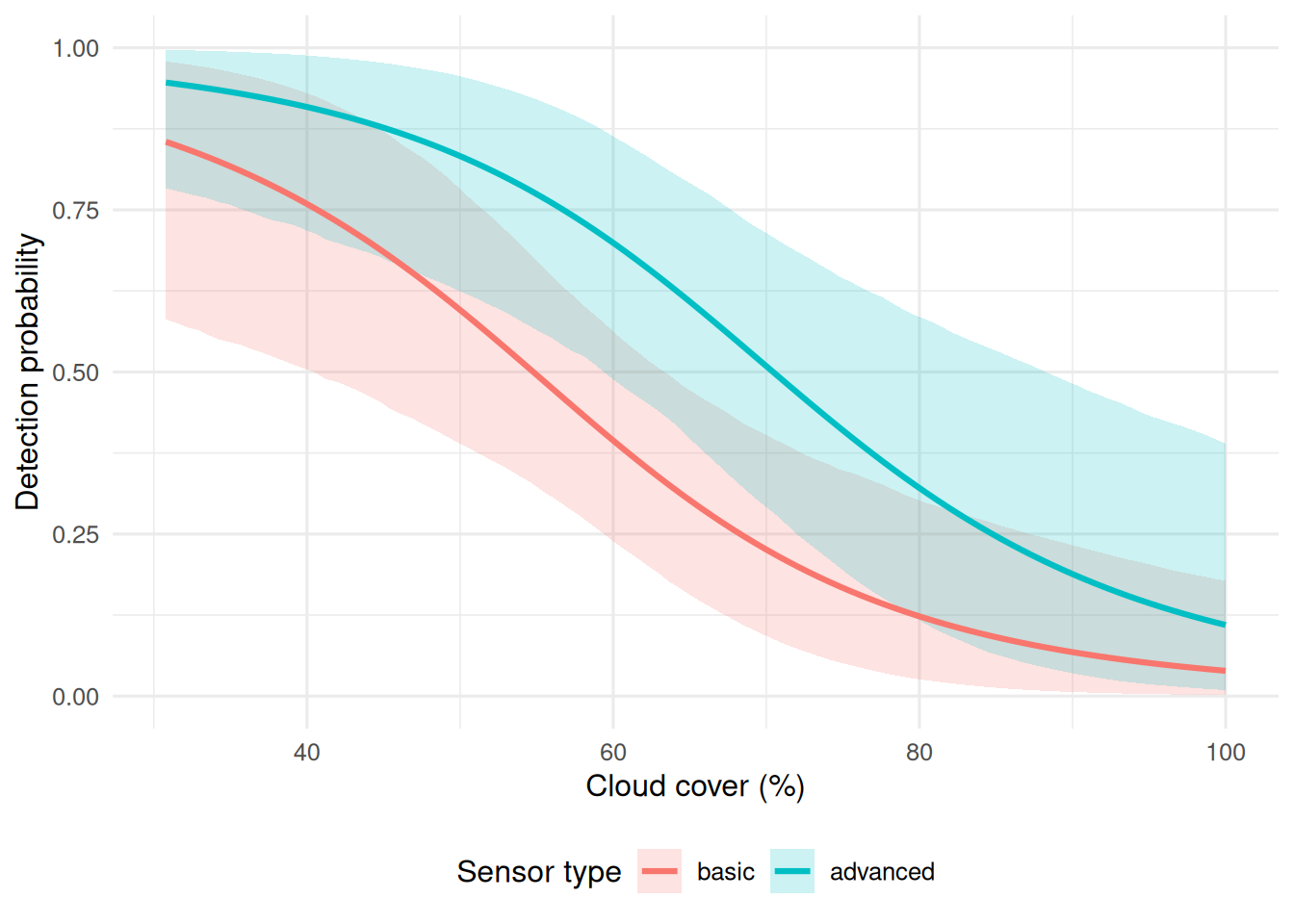
Figure 5. Posterior predicted detection probability across cloud cover for basic and advanced sensors. Detection declines as cloud cover increases, while the advanced sensor remains associated with higher detection probability across most of the observed range.
This figure shows the clearest signal in the survey-level analysis. Detection probability declines as cloud cover increases, which is consistent with the expectation that poor viewing conditions reduce successful remote sensing. The advanced sensor also tends to maintain higher predicted detection probability than the basic sensor, suggesting that sensor type matters as well.
10 Naive versus detection-aware occurrence across site age
age_seq <- seq(min(site_df$site_age), max(site_df$site_age), length.out = 100)
age_seq_z <- (age_seq - mean(site_df$site_age)) / sd(site_df$site_age)
naive_newdata <- tibble(site_age_z = age_seq_z)
occurrence_newdata <- tibble(
site_age_z = age_seq_z,
region = factor("North", levels = levels(site_df$region))
)
epred_naive <- posterior_epred(
naive_fit,
newdata = naive_newdata,
re_formula = NA
)
epred_occurrence <- posterior_epred(
occurrence_fit,
newdata = occurrence_newdata,
re_formula = NA
)
naive_curve_df <- as_tibble(t(epred_naive)) |>
mutate(row_id = row_number()) |>
pivot_longer(cols = -row_id, names_to = "draw", values_to = "epred") |>
group_by(row_id) |>
summarise(
mean = mean(epred),
lower = quantile(epred, 0.025),
upper = quantile(epred, 0.975),
.groups = "drop"
) |>
mutate(site_age = age_seq, model = "Naive")
occurrence_curve_df <- as_tibble(t(epred_occurrence)) |>
mutate(row_id = row_number()) |>
pivot_longer(cols = -row_id, names_to = "draw", values_to = "epred") |>
group_by(row_id) |>
summarise(
mean = mean(epred),
lower = quantile(epred, 0.025),
upper = quantile(epred, 0.975),
.groups = "drop"
) |>
mutate(site_age = age_seq, model = "Detection-aware")
curve_df <- bind_rows(naive_curve_df, occurrence_curve_df)
ggplot(curve_df, aes(x = site_age, y = mean, color = model, fill = model)) +
geom_ribbon(aes(ymin = lower, ymax = upper), alpha = 0.18, linewidth = 0, color = NA) +
geom_line(linewidth = 1.1) +
coord_cartesian(ylim = c(0, 1)) +
labs(
x = "Site age (years)",
y = "Occurrence probability",
color = NULL,
fill = NULL
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")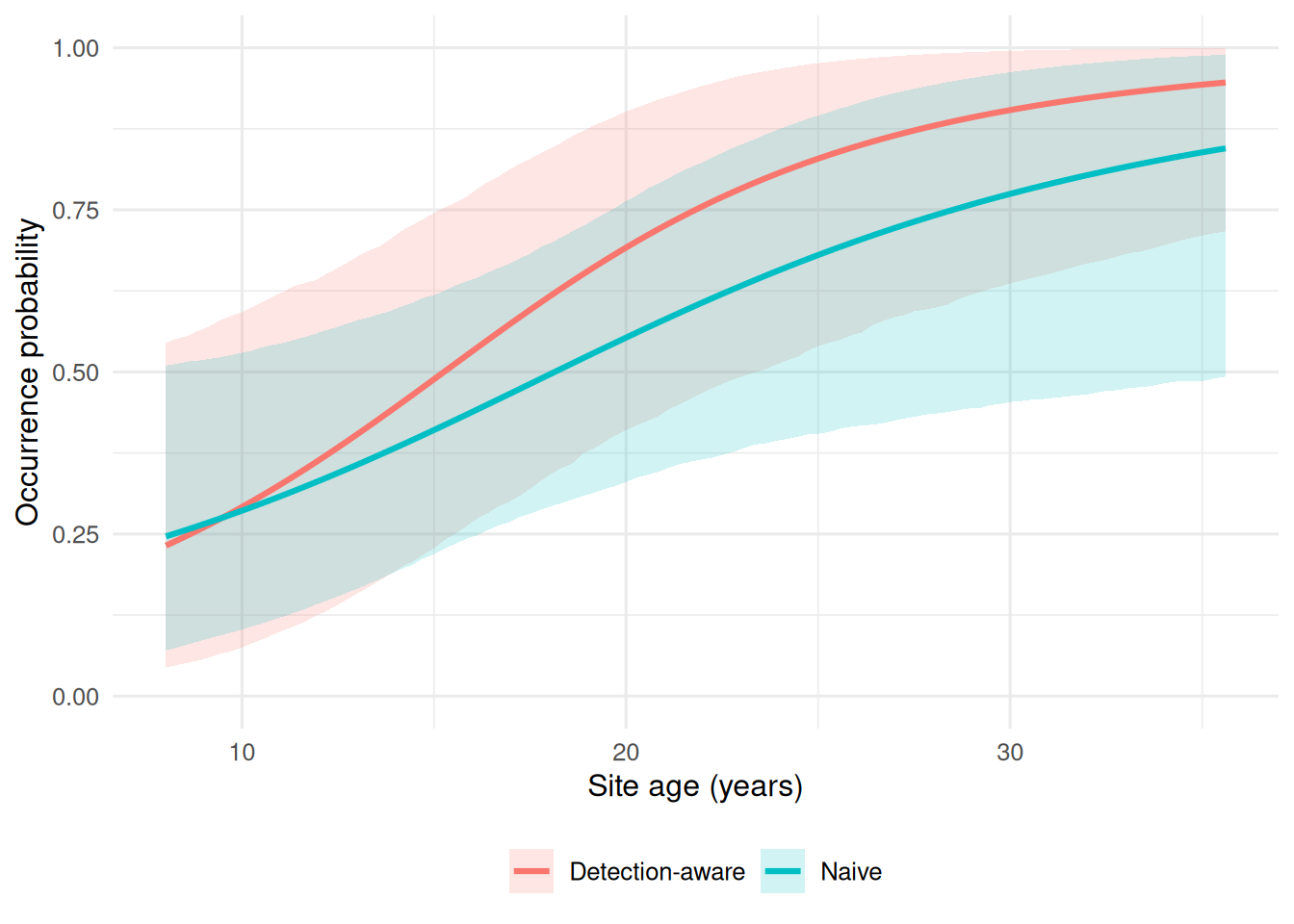
Figure 6. Naive versus detection-aware occurrence estimates across site age. Both models suggest higher leak probability at older sites, but the detection-aware analysis yields higher occurrence estimates by separating benchmark site status from observed detection.
Both site-level models indicate that older infrastructure is associated with higher leak probability. The difference is that the naive model relies on whether a site was ever detected, whereas the occurrence model uses benchmark-confirmed site status and also accounts for region-level structure. As a result, the detection-aware curve sits above the naive curve across much of the age range, showing how imperfect detection can bias occurrence downward when observed detections are treated as direct truth.
11 Benchmark Occurance
appendix_df <- site_naive_df |>
mutate(age_bin = cut_number(site_age, n = 4)) |>
group_by(age_bin) |>
summarise(
true_occurrence_prev = mean(true_event),
observed_ever_detected_prev = mean(ever_detected),
.groups = "drop"
) |>
mutate(age_bin = fct_inorder(as.character(age_bin)))
ggplot(appendix_df, aes(x = age_bin)) +
geom_point(aes(y = true_occurrence_prev, shape = "Benchmark occurrence"), size = 3) +
geom_line(aes(y = true_occurrence_prev, group = 1, linetype = "Benchmark occurrence")) +
geom_point(aes(y = observed_ever_detected_prev, shape = "Observed ever detected"), size = 3) +
geom_line(aes(y = observed_ever_detected_prev, group = 1, linetype = "Observed ever detected")) +
coord_cartesian(ylim = c(0, 1)) +
labs(
x = "Site-age bin",
y = "Prevalence",
shape = NULL,
linetype = NULL
) +
theme_minimal(base_size = 12) +
theme(legend.position = "bottom")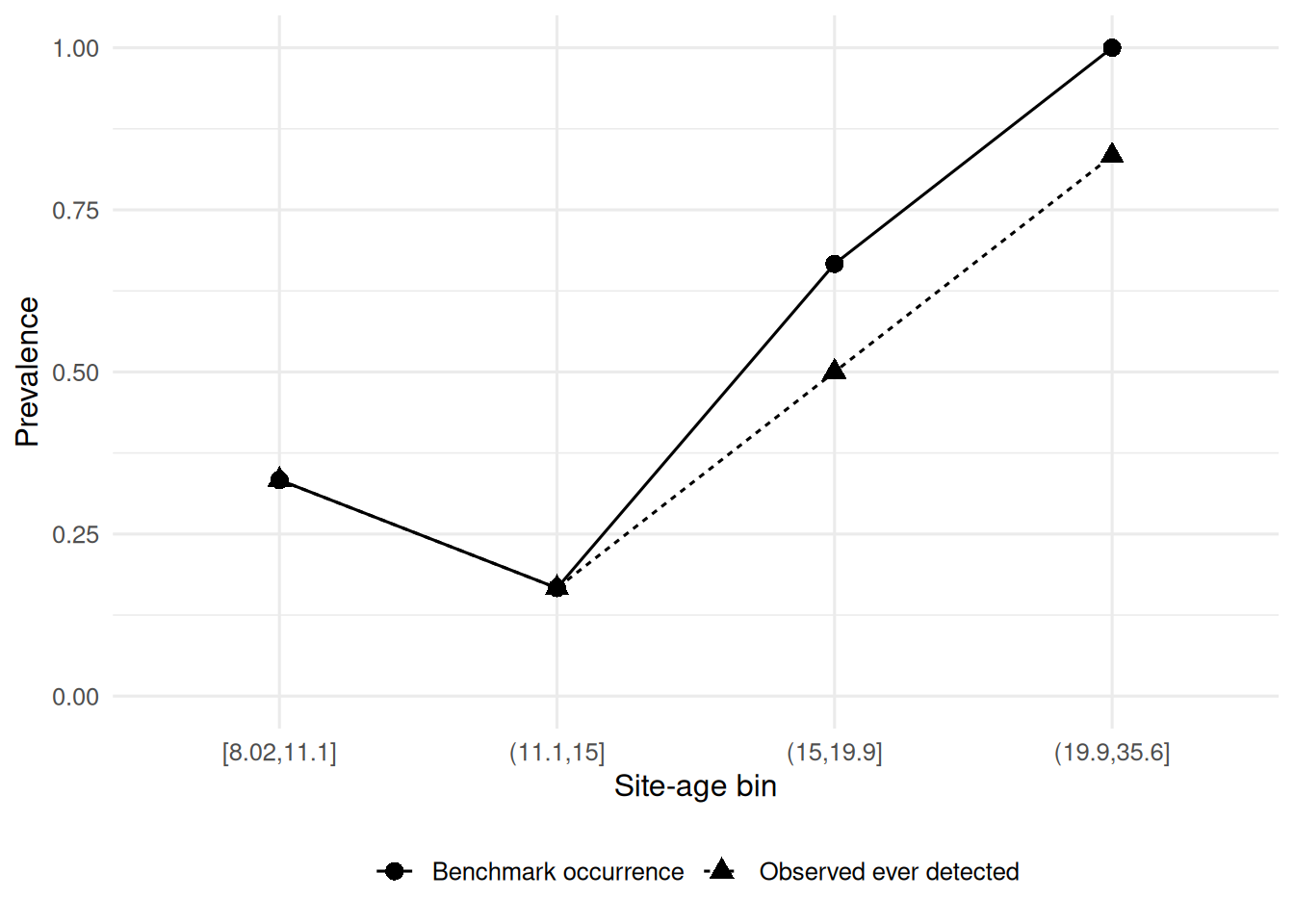
Figure 7. Observed ever-detected prevalence and benchmark occurrence prevalence across site-age bins. The gap between the two curves summarizes the downward bias introduced when nondetection is treated as absence.
This figure provides a compact summary of the same contrast shown in Figure 6. Across age bins, benchmark occurrence is generally higher than observed ever-detected prevalence, especially where the probability of occurrence is greatest. This supports the broader conclusion that repeated-survey datasets should not be analyzed as though every zero means the same thing.
12 Conclusion
This analysis shows why imperfect detection matters in methane monitoring. In a repeated-survey dataset, a nondetection can represent either true absence or a missed detection, and treating those outcomes as equivalent leads to lower estimated occurrence. The naive model captured the broad age pattern in the data, but it understated leak probability because it relied only on whether a site was ever detected. The detection-aware strategy gave a more informative picture by separating benchmark site status from survey-level detection and by allowing regional baselines to vary.
The fitted models were intentionally simple: Bernoulli-logit models, one random-intercept structure, weakly regularizing priors, posterior summaries, and basic posterior predictive checks. Even within that limited framework, the analysis suggests that older infrastructure is associated with higher leak probability, cloud cover reduces detection, and sensor type can affect detectability. The broader lesson is clear: environmental monitoring data are shaped both by the system being observed and by the process used to observe it. When those two sources of variation are collapsed into a single observed outcome, inference becomes easier, but also less reliable.
13 Appendix
14 Session checks
packageVersion("brms")[1] '2.23.0'packageVersion("posterior")[1] '1.7.0'sessionInfo()R version 4.5.3 (2026-03-11)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
time zone: UTC
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices datasets utils methods base
other attached packages:
[1] posterior_1.7.0 brms_2.23.0 Rcpp_1.1.1 lubridate_1.9.5
[5] forcats_1.0.1 stringr_1.6.0 dplyr_1.2.1 purrr_1.2.1
[9] readr_2.2.0 tidyr_1.3.2 tibble_3.3.1 ggplot2_4.0.2
[13] tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] gtable_0.3.6 tensorA_0.36.2.1 xfun_0.57
[4] QuickJSR_1.9.0 inline_0.3.21 lattice_0.22-9
[7] tzdb_0.5.0 vctrs_0.7.2 tools_4.5.3
[10] generics_0.1.4 stats4_4.5.3 parallel_4.5.3
[13] pkgconfig_2.0.3 Matrix_1.7-5 checkmate_2.3.4
[16] RColorBrewer_1.1-3 S7_0.2.1 distributional_0.7.0
[19] RcppParallel_5.1.11-2 lifecycle_1.0.5 compiler_4.5.3
[22] farver_2.1.2 Brobdingnag_1.2-9 codetools_0.2-20
[25] htmltools_0.5.9 bayesplot_1.15.0 yaml_2.3.12
[28] pillar_1.11.1 crayon_1.5.3 StanHeaders_2.32.10
[31] bridgesampling_1.2-1 abind_1.4-8 nlme_3.1-169
[34] rstan_2.32.7 tidyselect_1.2.1 digest_0.6.39
[37] mvtnorm_1.3-6 stringi_1.8.7 reshape2_1.4.5
[40] labeling_0.4.3 fastmap_1.2.0 grid_4.5.3
[43] cli_3.6.5 magrittr_2.0.5 loo_2.9.0
[46] utf8_1.2.6 pkgbuild_1.4.8 withr_3.0.2
[49] scales_1.4.0 backports_1.5.1 bit64_4.6.0-1
[52] timechange_0.4.0 rmarkdown_2.31 matrixStats_1.5.0
[55] bit_4.6.0 gridExtra_2.3 hms_1.1.4
[58] coda_0.19-4.1 evaluate_1.0.5 knitr_1.51
[61] rstantools_2.6.0 rlang_1.2.0 glue_1.8.0
[64] renv_1.2.0 vroom_1.7.1 jsonlite_2.0.0
[67] plyr_1.8.9 R6_2.6.1 13.1 Appendix A: Site-Level Data Dictionary
| Variable | Type | Description |
|---|---|---|
| site_id | factor | Unique identifier for monitoring site |
| region | factor | Region containing the site |
| site_age | numeric | Infrastructure age in years |
| site_age_z | numeric | Standardized site age |
| true_event | integer | Benchmark-confirmed methane leak status (0/1) |
13.2 Appendix B: Survey-Level Data Dictionary
| Variable | Type | Description |
|---|---|---|
| site_id | factor | Site identifier |
| survey_id | factor | Survey occasion within one monitoring window |
| region | factor | Region of site |
| site_age | numeric | Infrastructure age in years |
| site_age_z | numeric | Standardized site age |
| true_event | integer | Benchmark-confirmed site status, fixed across surveys |
| cloud_cover | numeric | Cloud cover percentage during survey |
| cloud_cover_z | numeric | Standardized cloud cover |
| sensor_type | factor | Sensor class: basic or advanced |
| sensor_advanced | integer | Indicator for advanced sensor (0/1) |
| detected | integer | Observed detection outcome (0/1) |
13.3 Appendix C: Model Parameter Dictionary
| Model | Parameter | Interpretation |
|---|---|---|
| Naive fit | Intercept | Baseline log-odds of ever being detected |
| Naive fit | Site age | Effect of standardized site age on ever-detected status |
| Occurrence fit | Intercept | Baseline log-odds of benchmark occurrence |
| Occurrence fit | Site age | Effect of standardized site age on benchmark occurrence |
| Occurrence fit | Region SD | Between-region standard deviation in occurrence intercepts |
| Detection fit | Intercept | Baseline log-odds of detection given benchmark-confirmed presence |
| Detection fit | Cloud cover | Effect of standardized cloud cover on detection |
| Detection fit | Advanced sensor | Effect of advanced sensor on detection |